
Case Studies
Date
Reading time
3 min
Author
When quantization stops being marginal: a real-world extraction measurement
A note from Singularity.Inc on local LLMs for structured extraction from unstructured text
Singularity.Inc — engineering notes
A common claim in the local-LLM literature is that quantization’s cost on accuracy is marginal — a few percentage points, sometimes within noise. On well-separated classification and short-form QA benchmarks, that’s defensible. On a real-world interpretive-extraction task we ran across nine open-weight models, it wasn’t. The same architecture (qwen3.6 35B-A3B) at q4 gave recall 0.688; at bf16, recall 1.000 — same input, same prompt, same evaluator, same chunking. We aren’t claiming the literature is wrong in general. We’re showing where its framing didn’t fit our task, and what that looks like in numbers.
The problem we were solving
Extracting structured items — decisions, action items, entities, claims — from messy unstructured text is one of the workhorses of applied LLM work. We need each real item recovered (recall) without inventing items that were never said (precision). The catch on our corpus: the source uses near-identical surface forms for items that should count and items that shouldn’t. Telling “Approval of the financial statement for May” (a real decision) from “the resolution was adopted unanimously” (procedural noise) requires interpretive judgment, sentence by sentence.
The setup
Nine local Ollama models, one fixed sample, same prompt, same evaluator (a frontier judge at samples=3), same reference set hand-pulled from a small but adversarial corpus, same chunking.
Only the model varied. Families spanned qwen2.5, qwen3.5, qwen3.6, gemma4, gpt-oss, mistral-medium, and granite4.1; sizes ran from 23 GB to 81 GB on disk. We scored micro-recall and micro-precision plus a separate fabrication count, which stayed near zero across the board. Figure 1 shows where each model landed.
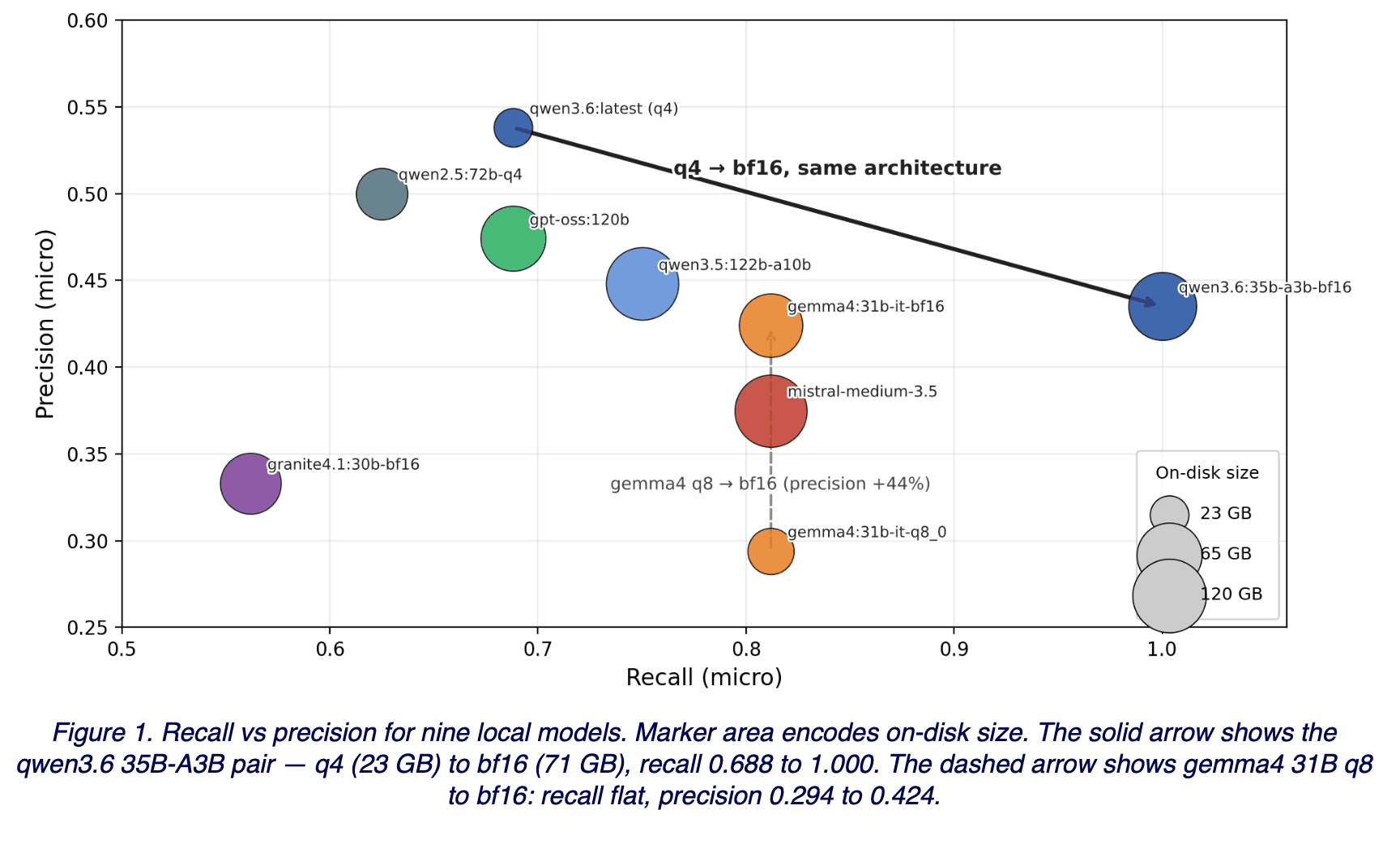
The measurement
The headline is the gap, not the winner. Within the same architecture (qwen3.6 35B-A3B MoE), going from q4 (23 GB on disk) to bf16 (71 GB) moved recall from 0.688 to 1.000 — a 31-point gap on the items we cared about. Precision moved in the opposite direction, from 0.538 to 0.435.
When we inspected the q4 misses, the pattern was consistent: q4 was systematically dropping the substantive items — “Approval of <X>” with a concrete subject and amount — while still surfacing the bare procedural shells (“the resolution carried”). bf16 catches both. The precision drop reflects the model surfacing additional candidates, some of which are genuine false positives. So bf16 isn’t more cautious — it’s more capable of the interpretive call, which shows up as both higher true-positive volume and higher candidate volume.
The same operation on a different family confirms the pattern: gemma4 31B q8 → bf16 left recall flat at 0.812 but lifted precision from 0.294 to 0.424. Opposite direction, same root cause — the higher-fidelity weights resolved borderline calls the lower-precision weights couldn’t.
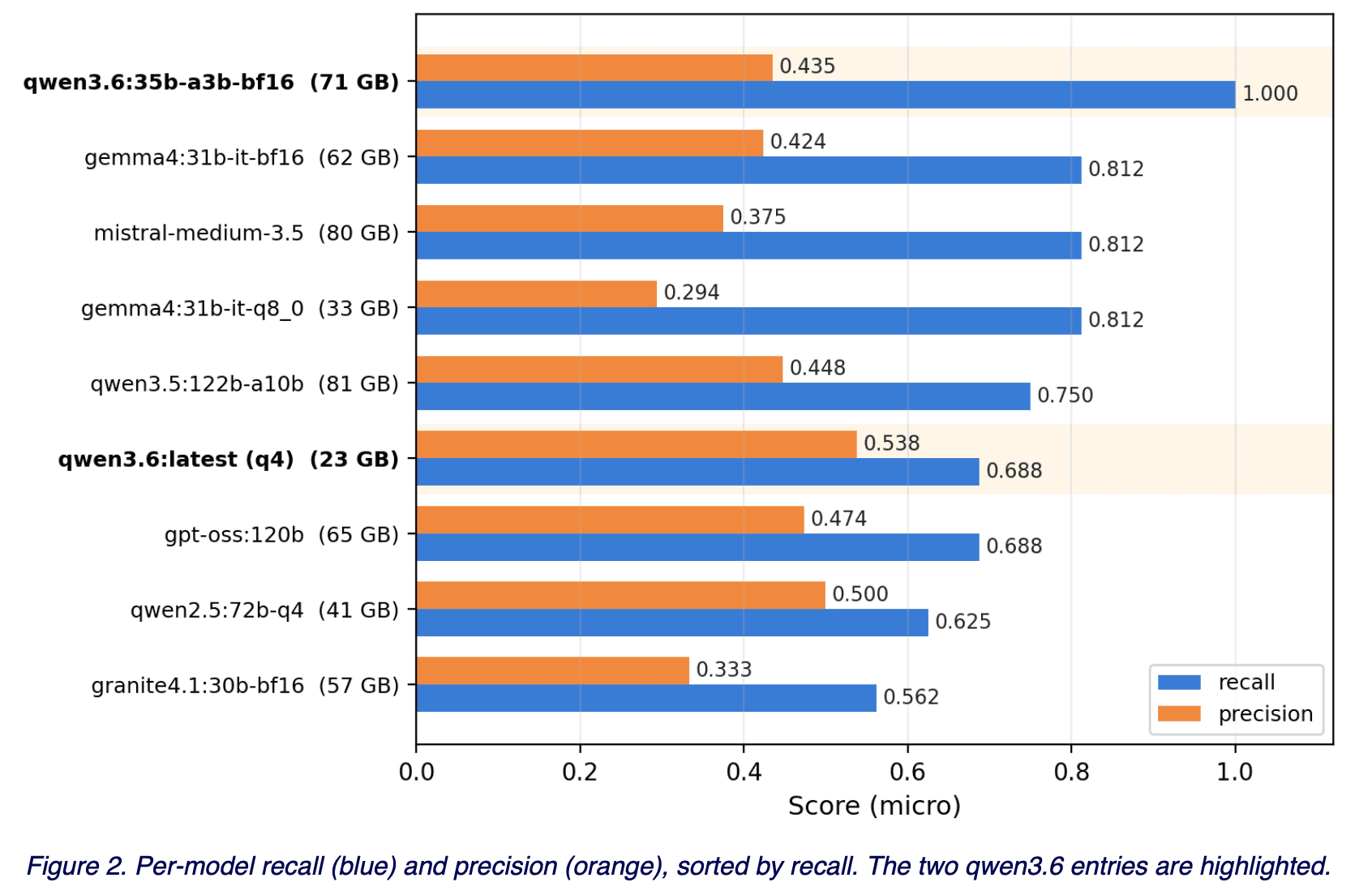
Why we think the ‘marginal’ framing missed this
The “small accuracy tax” framing of quantization is calibrated on benchmarks where labels are well-separated and judgments are crisp — classification, factual recall, short-form QA. Interpretive extraction is a different regime: the model has to discriminate between near-identical surface forms based on what they mean, sentence by sentence. That kind of fine semantic distinction appears to be exactly what lower-bit weights stop being able to represent reliably. The result, on our task, was a 31-point recall gap on a fixed input set — not within noise, not a few percentage points. We don’t think this contradicts the standard quantization-benchmark literature; we think it’s a workload class that literature doesn’t usually cover. The practical implication for anyone running local LLMs on similar tasks: RAM is the constraint, not parameter count, and the ‘right model’ can be the same model you’re already running, at higher fidelity.
Operating points by RAM tier
If you’re running a similar interpretive-extraction workload, here’s where our nine results land against four common Mac-class RAM tiers:
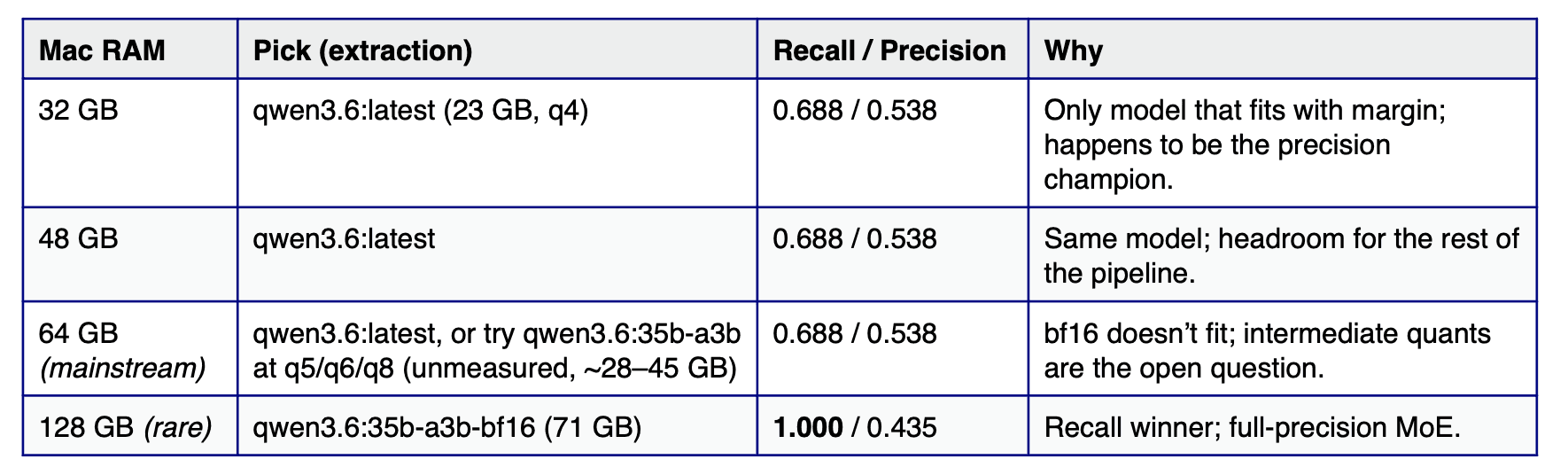
The 64 GB tier is the open question: bf16 doesn’t fit, but the same MoE architecture at q5_K_M / q6_K / q8_0 (likely ~28–45 GB on disk) plausibly recovers a significant share of the recall lift. We haven’t measured those quants yet — that’s our next bench.
What this isn’t
One adversarial corpus, one task type, one prompt, one judge. We aren’t claiming the marginal-tax framing is wrong in general — we’re claiming it didn’t fit ours, and we suspect that’s true for other interpretive-extraction workloads where surface forms collide. Fabrication (separately measured) was effectively zero across all nine models; the precision movements here are over-eager extraction of real text, not hallucination. If you’re doing similar work, this is a directional signal worth pressure-testing on your own data — not a leaderboard. Happy to compare notes.
Dr Vinicius Ferraz, CAIO Singularity.Inc


